MakeoverMonday 24-09-2018
September 30, 2018
MakeoverMonday was focussed on global gender equality, with a dataset from Equal Measures 2030 which consisted of survey results asking global advocates about their priorities and converns around existing data sources.
I’ve been really struggling for time this week, so ended up looking into this nearly a week late, so this post will be brief.
The original report included the following two visualisations:
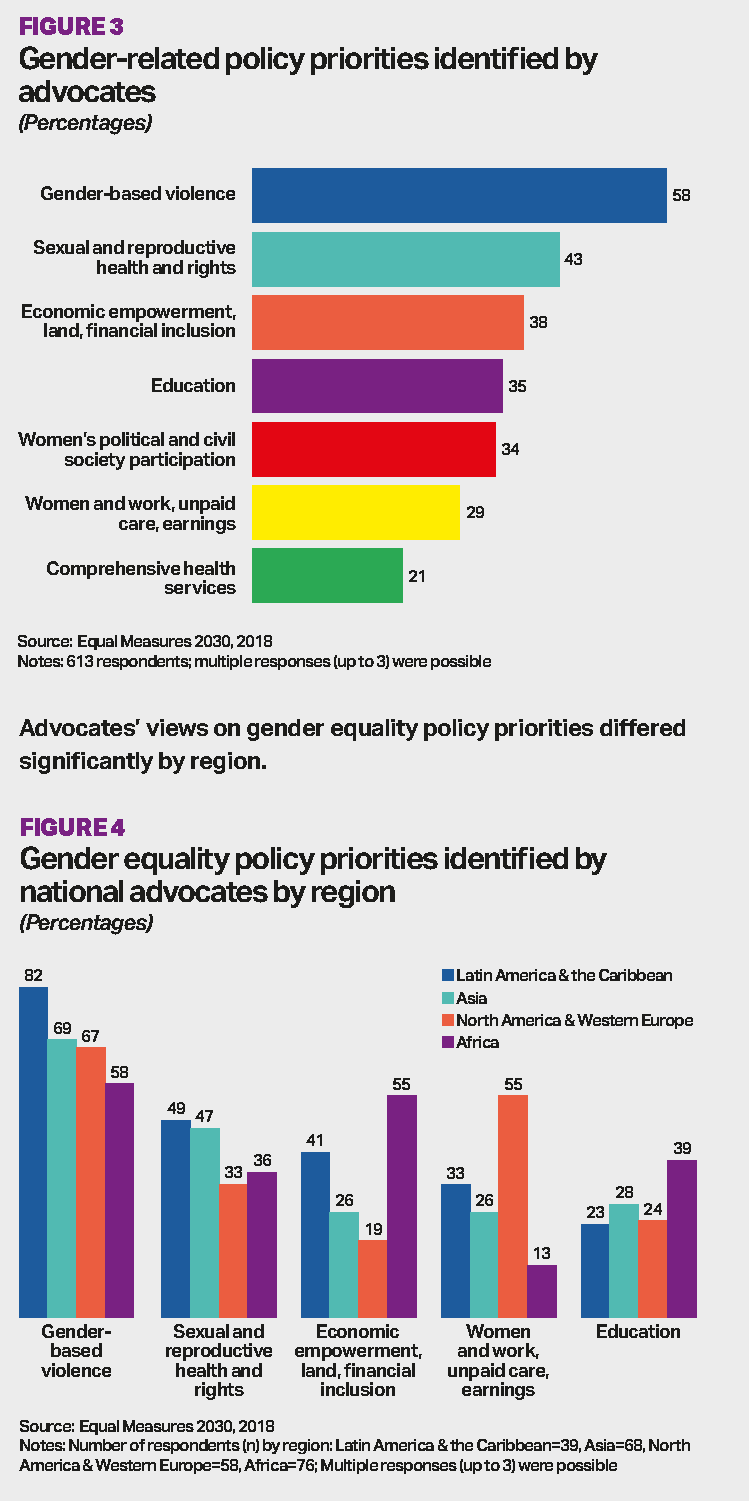
What I like about this:
- The use of labelled bars in the first graph to make it easy to read off the values.
- A horitontal bar chart to make long text labels easy to read.
What I don’t like about this:
- The large number of colours in the first graph is a bit distracting.
- I’d probably add a % sign to all the labels to make it clear what they represent.
- In the second graph, it takes quite a lot of work to get to a ranking for each region.
- I think that there are probably a few too many data labels in the second graph, and a labelled axis might better here.
I tried to improve in these particular areas when creating my version.
As well as showing the two key bits of data which feature in the original visualisation, I wanted to try showing the Likert scale (1-5 scale) data which was also part of the dataset. I revisitted the excellent discussion of the best way to chart this sort of information from DataWrapper - on this occasion I decided to go with the recommendation made at the end of the article to use stacked bars with dual scales.
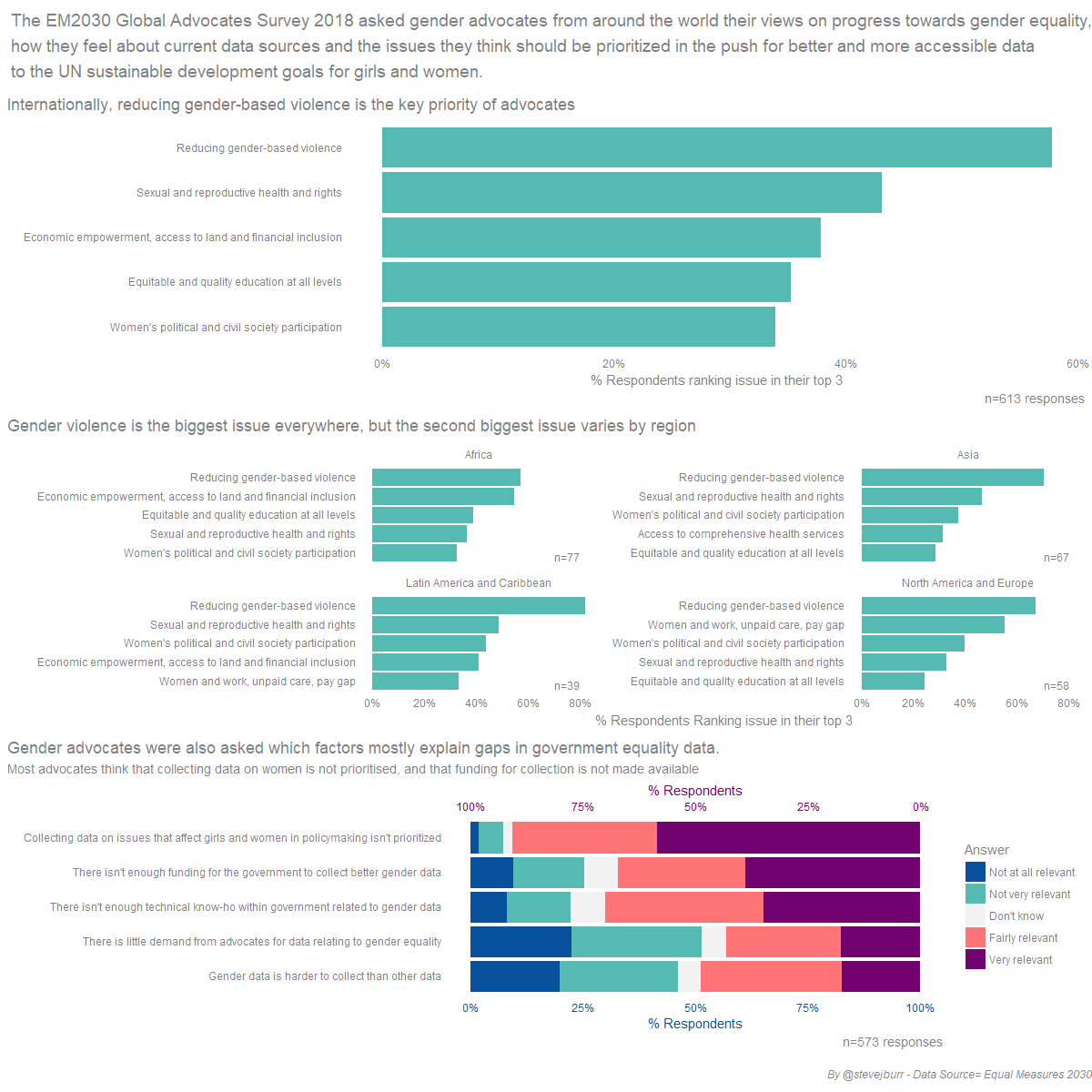
What I don’t like about what I did:
- I wasn’t able to get hold of the original font used for the reports, and didn’t have time to try and more closely match the style used by EM2030.
- The text sizes are too small.
- There’s not enough space between the three visualisations.
- In general, it’s too cluttered.
- The different parts don’t flow together as one cohesive piece as well as I would like.
What I like about what I did:
- I prefer the small multiples approach to showing the regional data to the original, it makes rank comparisons easier and I think grouping by region makes more sense than grouping by question. However, this is definitely a matter of taste.
- The visualisation of the Likert scale data worked well, and was pretty quick to do in the end. I prefer this approach to most of the other ones I’ve seen in other submissions, for the reasons explained in the previously linked article.
Looking back now, I think this could be reduced to only two visualisations instead of three. The top “overall view” could be incorporated as a benchmark into the regional plots, for example by using a bullet chart or just a reference line. This would free up space and help with the amount of information being shown. Alternatively, the total could be added as an extra view within the region grid (perhaps with an “other regions” plot to keep the numbers even).
As a result of this visualisation, I got a bit more confident with arranging multiple visualisations on a single page using R and how to get the alignment of different pieces of text right - but this still took ages.
I also found it fairly frustrating how challenging it was to get R to order bars within a facetted plot - eventually I found some very useful code from David Robinson here which was really helpful.
The original data can be found here and my code is here. If you’d like to discuss this more, then find me on Twitter.